
운영체제
main memory
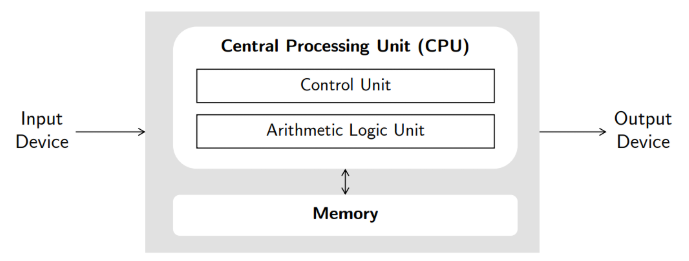
폰 노이만 구조 :
OS한테 파라미터 넘기는 방법 :
- 가장 간단한 방법은 registers에 저장해서 사용 (eax ebx 등등)
- parameter가 register 개수 초과한 경우에는 block이나 stack.
- block은 memory에 저장하고 그 주소를 전달해줌.
- stack은 stack memory에 push하고 꺼내쓰는 방식.
main memory는 바이트마다 address가 있다.
process
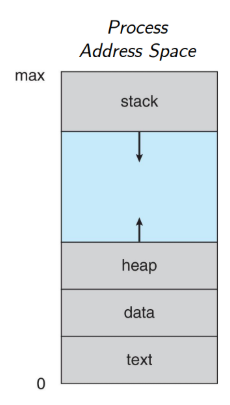
프로그램은 명령어 리스트를 파일에 저장한 수동적인 존재,
프로세스는 다음에 실행될 명령어(프로그램 카운터라고 함)와 관련 리소스들을 가진 능동적인 존재 (실행중인 프로그램)
하나의 프로그램으로 여러 프로세스 실행 가능.

process control block은 프로세스 하나당 하나. stack 위쪽 커널 메모리에 존재한다.
- process state : ready(scheduling 기다리는), running, waiting(i/o or event wait)
- program counter : 프로그램의 어디 실행하고 있었는지
- registers : 레지스터 쓰던 값들 백업해 둠.
Process Scheduler가 cpu에 process를 할당. (cpu를 최대한 활용하는 것을 목표로)
Context Switch : cpu가 어떤 process 처리하다가 다른 process 불러오는 과정
(기존 Process 정보를 그 process의 PCB에 저장하고, 불러오려는 process의 PCB의 정보 불러와서 실행하는 것.)
기존 Process 저장하고, 다른 Process 불러오는 그 과정은 프로세스 돌아가지 않는 시간(Dispatch Latency)으로, 오버헤드임.
오버헤드 줄이는 방법으로 Hyperthreading : CPU에 Process의 state 저장 공간(레지스터)을 하나 더 두는 것. 이러면 context switching을 덜 할 수 있음. (하나의 코어에서 한 프로세스가 context switching 할 때 다른 하나의 프로세스를 실행하면 됨)
프로세스의 Parent - Children 관계 : Process가 Process를 만들면 Parent-Children. (리소스를 일부 또는 전부 공유하거나 안 할 수 있음)
Children이 exit() 하는데 이걸 받아주는 Waiting Parent가 없으면 Children은 Zombie process가 됨.
Parent가 Children 보다 먼저 종료되면, Children은 Orphan process가 됨.
thread
Thread : 일반적으로 하나의 코어에서 실행될 수 있는 단위
여러 Thread를 실행하는 걸 Multithread라고 함. (싱글 코어든 멀티 코어든 여러 thread 동시에면.)
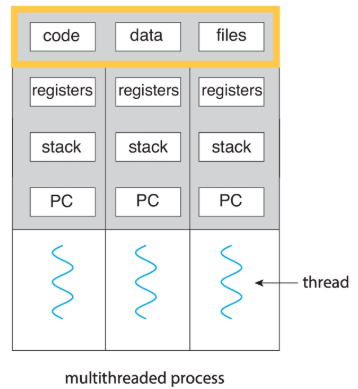
이런 식이다.
각 thread 당 하나의 stack을 쓰고, code, data section은 공유한다.
프로세스(또는 스레드)에 할당된 전체 스택 공간을 초과했을 때를 스택 오버플로우라고 한다.
함수 하나의 스택 공간은 스택 프레임이라고 하며, 이걸 벗어나는 것은 스택 오버플로우가 아니라 버퍼 오버플로우 또는 스택 스매싱이라고 한다.
pcb는 프로세스당 하나이고 tcb는 thread당 하나이다.
process context-switching보다 thread context-switching이 더 빠르다. (data를 공유하기도 하고, 이에 따라 cache memory에 있는 data를 재사용 가능)
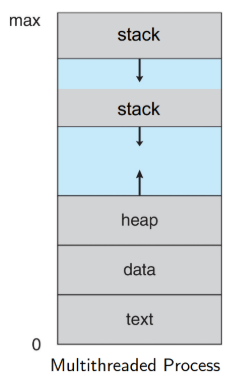
Multithread 종류
concurrent : 여러 thread를 작업. (하나의 코어에서 번갈아가면서)
parallel : 여러 thread를 동시에 작업
스케쥴링
- First Come First Served : burst time 긴 걸 먼저 하면 나머지의 remain time 늘어남
- Shortest job first : burst time 짧은 것부터. (burst time 확실하면 이게 최적)
- Shortest remaining time : Arrival time까지 고려해서 burst time의 남은 시간을 고려해서 스케쥴링
- Round Robin : 시간 정해두고 돌아가면서
- Priority : 우선 순위 높은 것부터
- Priority & Round Robin : 우선 순위 높은 것부터 Round Robin
Race condition
Process간 커뮤니케이션은 메모리 공유 방식 또는 메세지 방식으로 가능
메모리 공유 방식의 경우 개발자가 직접 프로세스가 동시에 접근해서 문제가 생기지 않게 해 줘야 한다. (동기화)
각 프로세스에 critical section (파일 수정, 전역변수 수정 등을 하는 코드 부분)가 있음.
Critical section problem 푸는 solution의 조건
- Mutual Exclusion : critical section 하고 있는 process 있을 땐 다른 process가 critical section 못 들어가야 함.
- Progress : critical section 하고 있는 process 없을 땐 process가 critical section에 들어갈 수 있어야 함.
- Bounded Waiting : critical section에 들어가고자 요청했는데 무한정 대기하는 경우가 없어야 함.
solution 종류
- Interrupt-based solution : Entry section일 때 interrupts disable하고 Exit section일 때 interrupts enable 하는 거. ⇒ 이건 core 여러 개면 다른 core에서 수정할 수도 있음
- One software solution : 만약 j턴 왔는데, j가 critical section 할 준비가 안 되어 있으면 critical section 하고 있는 process 없을 때도, 기다리는 i의 턴이 오지 않음.

- Peterson’s Solution (모두 해결, 중요) : 턴만 고려하는 게 아니라, critical section 쓸 건지 체크 함.

근데 프로세서가 맘대로 flag와 turn 변경 순서를 바꿔버리면 문제가 생김. 그래서 이걸 잡아줘야 함.
그 방법에는
- memory_barrier()
- atomic
- mutex
동기화 예제
- Bounded-buffer problem
n개의 버퍼가 각각 하나의 아이템만 가질 수 있고, Producer가 아이템을 넣고 Consumer가 빼가는 구조인 경우.
- Semaphore mutex : Mutual exclusion for accesses(한명 접근 중이면 다른 애 못 들어오게 막는 거) 초기값 1 저장함. 접근 중이면 0인 거.
- Semaphore full : 아이템이 차 있는 버퍼의 개수를 카운팅하는 Semaphore임. 그래서 초기값 0. 모두 비어 있으니깐.
- Semaphore empty : 비어있는 버퍼 개수 counting하는 semaphore 초기값 n(버퍼 크기)

wait() : 0보다 작거나 같으면 기다리다가, 0보다 커지면 줄이는 애
signal () : 늘리는 애
- Readers-writers problem
Reader : 읽기만 가능
Writers : 읽기, 쓰기 가능
reader 우선 :
- integer read_count : 현재 읽고 있는 reader 수. 초기값 0
- semaphore mutex : 초기값 1. reader가 읽을 수 있는 상태인가.
- semaphore rw_mutex : 초기값 1. writer가 읽을 수 있는 상태인가.
reader :

writer :
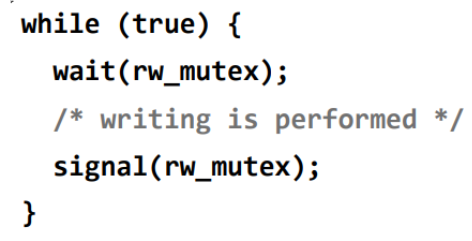
- Dining-Philosophers problem

상태:
- 생각을 하거나
- 음식을 먹거나
제한:
- 바로 옆 사람과는 소통하지 않는다.
- 음식을 먹으려면 왼쪽 오른쪽 2개의 젓가락을 집어야 함.
해결법
- 밥을 data set으로 생각.
- 각각의 젓가락 5개를 semaphore로 생각. (젓가락 하나씩 이니까 1로 초기화)
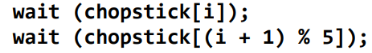
이렇게 하면 젓가락 다들 하나씩 들고 있으면 모두가 데이터에 접근하지 못 하는 데드락 발생 가능.

이렇게 하면 데드락 발생 안 함. starvation은 생길 수 있음. (양쪽이 번갈아가면서 먹으면)
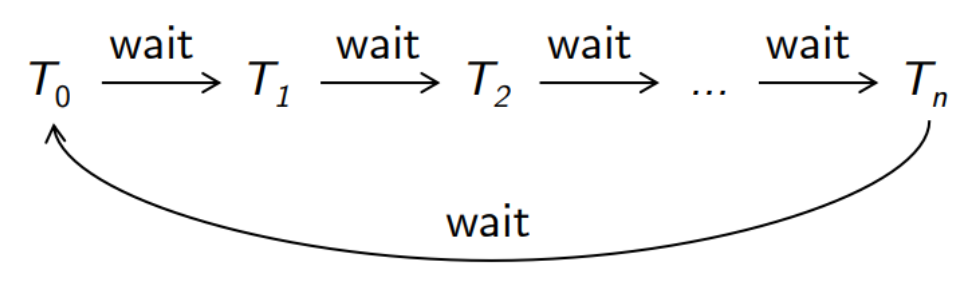
데드락 정의
- Mutual exclusion : 하나의 리소스는 한 번에 하나의 스레드만 사용할 수 있음
- Hold and wait : 하나 이상의 리소스를 보유한 스레드가 다른 스레드가 보유한 리소스를 획득하기 위해 대기 중임
- No preemtion : thread가 리소스를 가지고 있을 때 그 thread가 다 써서 넘겨주는 게 아닌 이상 리소스를 넘겨주지 못 함.
- Circular wait : 기다리는 사이클이 있음
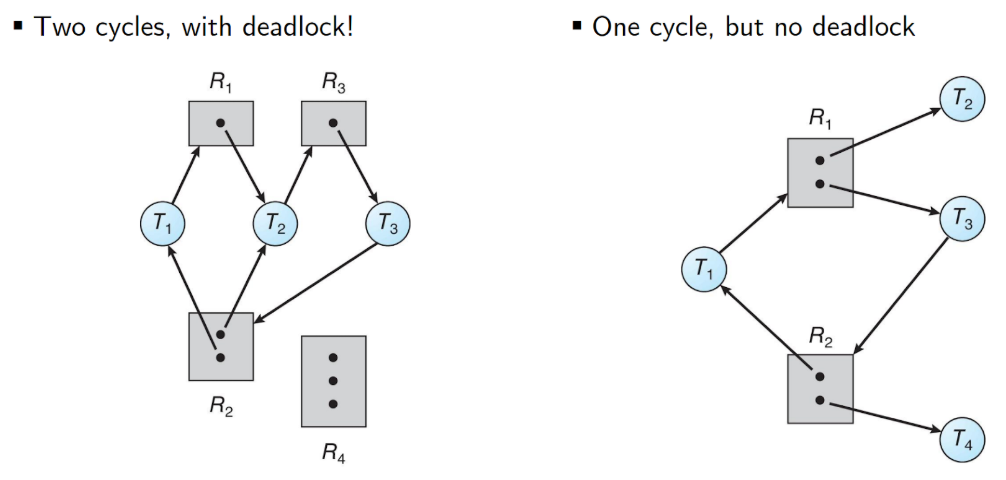
오른쪽은 T2, T4가 Release 가능하니깐 Deadlock 아님
Deadlock handling 방법
- 절대 deadlock 안 되게 하는 방법
- Deadlock prevention
- Deadlock avoidance
- Deadlock 발생할 수 있지만, 빠져나갈 방법 구현해 놓는 방법
- 그냥 무시하는 것
- Deadlock prevention : 데드락 네 가지 조건 중 하나를 발생하지 않도록 하는 것
- Circular wait을 무효화시키는 방법 : 리소스마다 unique number를 부여해서 리소스의 acquire 순서를 정해서 순환을 없애는 것.

여기서 S->Q, Q->S 여서 cycle 생겼는데 P0에 있는 Q를 P1에 있는 Q보다 더 빨리 실행되게
단점 : request 방식을 제한하는 거라 device utilization이 저하되거나 system 성능 저하를 유발할 수 있다.
- Deadlock Avoidance
thread가 각각의 리소스를 최대 얼마만큼 가져갈지 정해주는 것이다. 동적으로 체크를 해서 리소스를 할당을 할 때 데드락이 발생할 거 같으면 리소스 할당을 안 해주는 것이다.
앞에 release 가능한 resource와 아직 할당 안 된 리소스 합이 thread가 요청한 리소스보다 크면 safe!
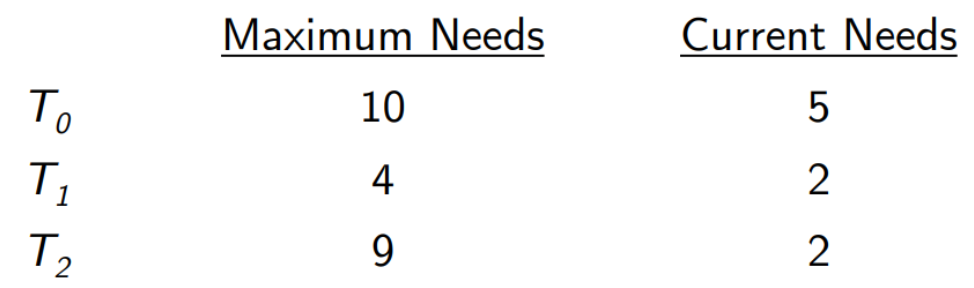
현재 리소스 12개 중 5개 2개 2개를 주고, 리소스 3개가 남아있는 상태임. ⇒ T1한테 2개 주면 4개 돌려받을 수 있으니 5개 됨. T1한테 5개 주면 10개 받을 수 있으니 10개 됨. T2한테 7개 줄 수 있으니깐 safe.
Main memory와 레지스터는 CPU가 직접 접근할 수 있는 저장소. (Main memory와 레지스터 사이에 Cache 있음)
레지스터 접근은 one CPU clock 안에 끝난다. 메인 메모리는 many cpu clock 걸린다. 메인 메모리 접근으로 생기는 타임 오버헤드를 memory stall이라고 함.
Logical address(virtual address) : 프로세스(cpu)가 보는 address
Physical address : 실제 메모리 공간 (메모리 사이즈에 따라 range 다름)
Address binding : process에 physical memory를 할당해 주는 것.
- compile time 바인딩 : 거의 아두이노 제외하고 쓰이지 않음.
- load time에 바인딩 : 컴파일 때 relocatable code (logical address) 만들어두고, 프로그램 불러올 때 physical address에 바인딩
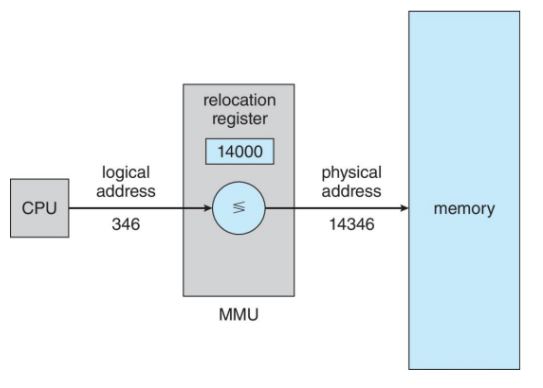
- execution time 바인딩 : MMU (logical address → physical address 해 주는 하드웨어)가 알아서 해 줌.
(MMU는 base and limit register 사용해서 계산)
Memory management methods
- Contiguous allocation
- Paging
Contiguous allocation
logical address + relocation register값 = physical address
CPU가 memory에 접근할 때 memory protection check 해 줌 (해당 프로세스가 다루는 메모리 주소 범위가 맞는지)
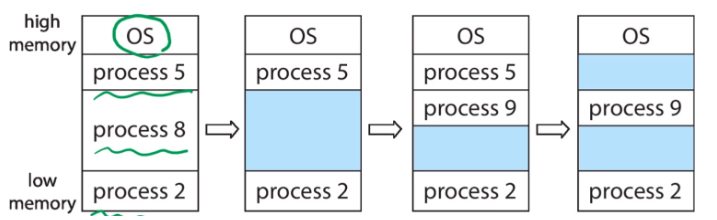
이렇게 프로세스 사이사이에 Hole(빈 공간)이 생길 수 있는데
- First-fit : 앞에서부터 들어갈 수 있는 크기면 들어감
- Best-fit : 들어갈 수 있는 크기 중 가장 작은 크기에 들어감. smallest leftover hole(정렬 안 돼있으면 전체 서치해야 한다는 단점)
- Worst-fit : 가장 큰 크기에 들어감. largest leftover hole. 나름 할당하고 가장 큰 덩어리가 남아서 더 효율적일 수도 있긴함.
그치만 일반적으로 speed와 storage utilization 측면에서 first fit, best fit이 worst fit보다 좋음
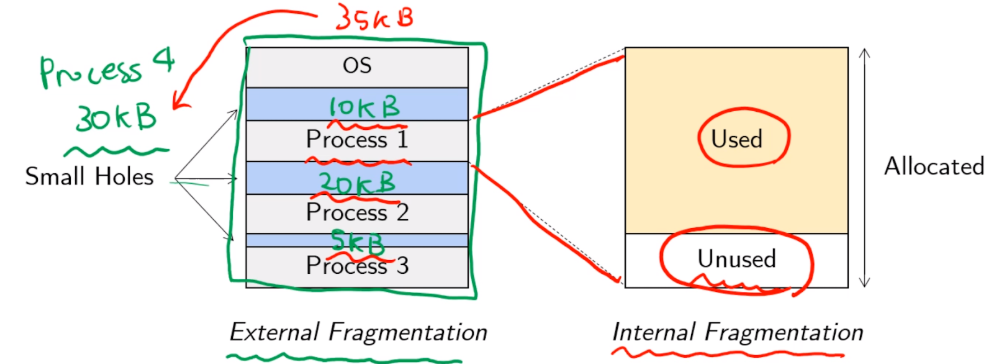
External Fragmentation (외부 파편화) : 프로세스 사이사이에 빈 hole들 다 합치면 하나의 프로세스가 더 들어갈 수 있는 공간인데, 나눠져서 못 들어가는 현상
External Fragmentation의 해결 방법은
- 재배치
- Paging
Paging
Physical memory를 frame 단위로 나눔.
Logical memory를 page 단위로 나눔. (frame과 같은 사이즈)
page를 frame에 할당.
이러면 contiguous하게 들어가지 않아도 됨.
프로세스마다 page table이 있어서 page들이 어떤 frame에 할당 되어 있는지 알 수 있음
Logical address : page index인 Page number, 한 page 내부에서의 index인 Page offset
이 Logical Address를 사용해서 main memory에 있는 데이터에 바로 접근하는 게 아니라, page table에 접근을 해서 해당 logical address에 해당하는 physical address 값을 얻고 나서 접근해야 함. 그래서 main memory에서 값 읽어올 때는 one cpu clock이 아닌 거임.
이 오버헤드를 줄이기 위한 TLB Cache가 있음. 이 Cache에 해당 Logical Address <=> Physical address 가 있다면 page table 안 가도 됨.
32bit machine 사용한다고 가정. Page size는 4096 bytes라고 가정.
그러면
page offset으로 12bits가 사용되고
page number로 20bits가 사용됨.
page 너무 많으니깐
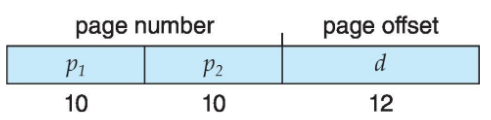
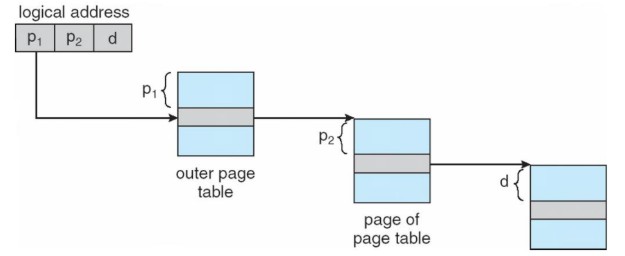
이렇게 가능 (메모리 접근 횟수 늘어남)
또는 Hashed Page Table 사용 가능
logical address의 page number에 hash function 적용 -> 거기에 연결된 list들 지나가면서 page number 같은 애 찾아서 mapped된 frame number 가져옴.
그래서 linked list에 연결된 각 element들은 (1) virtual page number (2) mapped frame number (3) pointer to the next element 필요
Swapping
main memory 한계일 때 backing store(disk)에 잠시 process 넣어뒀다가 다시 꺼내쓰는 거.
Standard swapping : process 통째로 backing store에 넣었다가 빼는 swapping
=> process가 만약 disk에 backing 되어 있는 경우라면 context switch time이 굉장히 오래 걸림.
Swapping with paging : page 단위로 backing store에 넣었다가 빼는 거
Virtual Memory
Physical memory 크기는 한정되어 있으므로, 그 크기만큼만 process를 실행할 수 있었다. 근데, 필요한 page만 physical memory에 올려두고 안 쓰는 부분은 backing store(disk)에 page out을 해두면 동시에 실행 가능한 process의 한계가 거의 없어진다.
장점
- 프로그램은 더 이상 물리적 주기억장치 크기에 제한을 받지 않는다.
- 프로그램을 적재하는데 걸리는 입출력 비용을 줄일 수 있다.
Virtual Address Space를 사용한 Virtual memory를 구현하는 방법
- Demand paging
- Demand segmentation
Demand Paging : backing store에 page 빼고 넣고 (Page in, Page out)
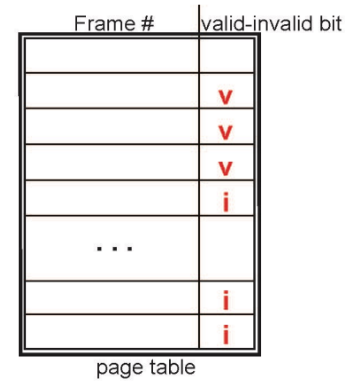
valid-invalid bit로 disk에 있는지 main memory에 있는지 확인
접근했는데 main memory에 없으면 main memory에 올려야 함 (Page in)
이거를 page fault라고 함. page fault는 오버헤드. 이거 고려해서 Page Replacement (page swap)
dirty bit : 수정한 내용 있는지 확인해서 swap시, 수정한 거 없으면 disk에 swap out 할 필요 없음.
lowest page fault를 목적으로 각 프로세스에 몇 개의 프레임을 할당해줄지 결정하는 알고리즘이 있다.
가끔 더 많은 frame을 할당해 줬을 때 page fault가 더 발생하는 경우도 있음.
Thrashing :
page-faults 자주 발생 -> page fault동안 cpu 사용 안 되니깐 cpu utilization 줄어들음 -> os가 착각해서 process를 더 늘림 -> 더 느려짐
Leave a comment